
Large Language Models Will Redefine B2B Software

“We should partner with […]. They come up in 70% of our sales calls.” That’s what the new COO at one of our companies told us last week after her second week on the job. It stuck in my mind because only a few years back, it would have been impossible for her to know this without spending hundreds of hours listening to call recordings. Now she can look at the data from every customer meeting in CI tools like Gong and Clari and immediately draw conclusions. It gives a flavor of what’s to come as large language models transform the application landscape.
Large Language Models (LLMs)
Natural language processing (NLP) is not new, but in the past five years it has made rapid progress thanks to the growing power of deep neural networks. Large language models are a new class of network that have been trained on massive bodies of text and, as a result, have the ability to understand, summarize, and even generate text from scratch.
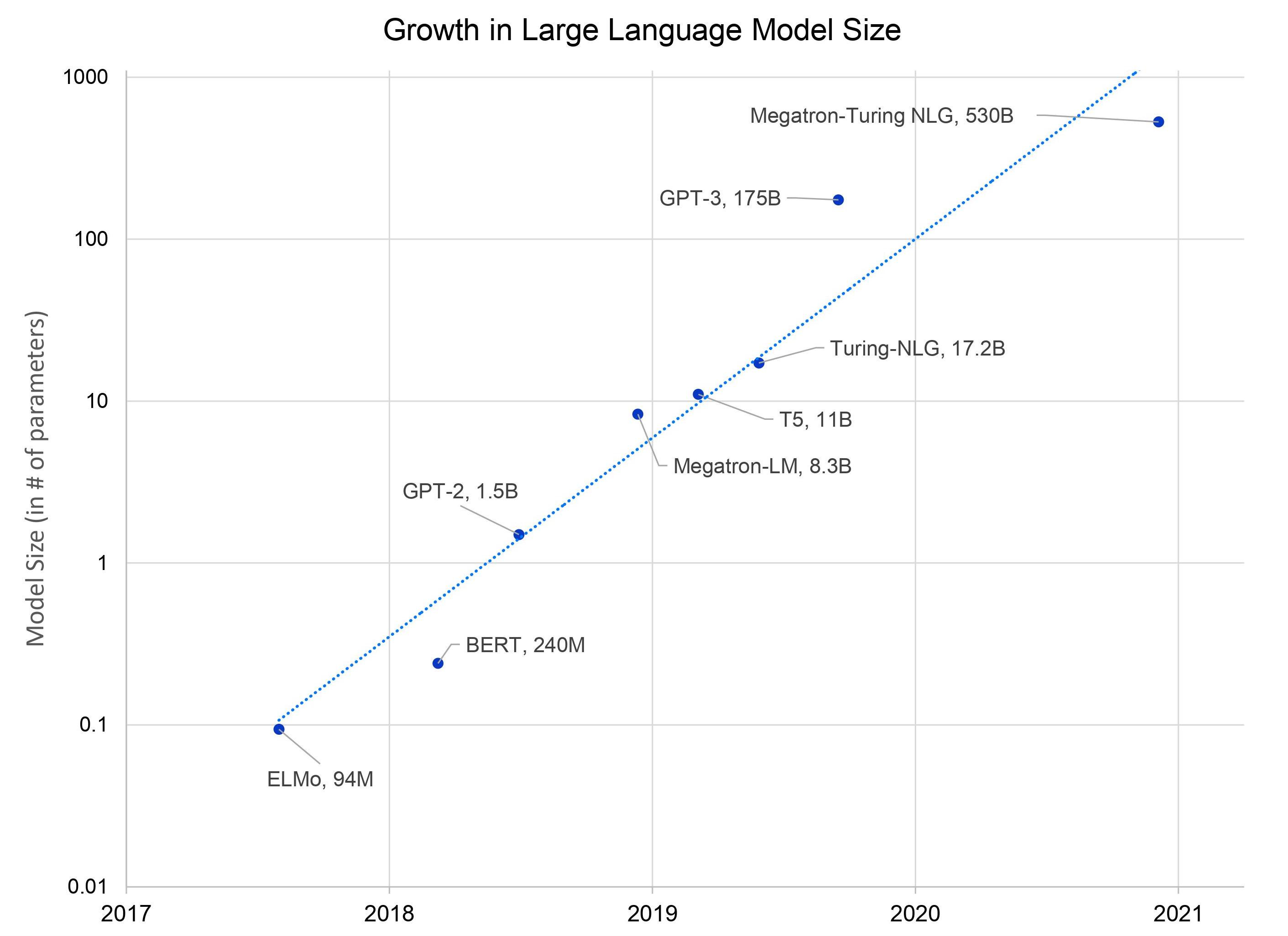
Parameters are a model’s internal variables that drive its decision making, similar to neurons in the brain. The more parameters used in a model, the higher level of complexity and sophistication that model is able to attain. The chart below, using a logarithmic scale, shows how drastically models have grown in size in only four years, from BERT’s 240 million parameters to GPT-3’s 175 billion. Today, barely a month goes by without some announcement of a new language model, as Google again showed this week.
My perspective is that open-source models will come to dominate the LLM space as opposed to proprietary models. Earlier this summer, BigScience, a LLM research workshop, released the BLOOM model, which was the first open-source, multi-lingual large language model, trained on $7M of publicly-funded hardware cost. This came about two years after the initial release of OpenAI’s proprietary GPT-3, which has similar capabilities. The one-time nature of training costs will continue driving the open release of future models for more broad and cost-effective public benefit.
Intelligent Applications with LLMs
Designing new language models or manufacturing machine learning hardware is highly cost prohibitive, and I expect it to remain dominated by a few large players including OpenAI, Google, Nvidia and a handful of others. However, we’ve already seen a Cambrian explosion of startups building applications on top of LLMs including everything from copywriting platforms to developer tools.

These improved language models allows applications to creep into new areas where they didn’t previously exist. For example, Jasper, Copy.ai, and other startups are using LLMs to automatically generate marketing material based only on topical guidance. Previously, writers had access only to blank canvasses and basic research tools; autogenerated copy is a net new product area.
Another example, GitHub Copilot allows developers to generate application source code from basic prompts, and it’s taken the developer world by storm since its release on June 21st. Many engineers (even very senior engineers) I’ve spoken with have said that Copilot is a game changer and that they will never develop without it again. Only a few months ago, machine learning played no role in the basic act of writing code.
One application of LLMs that has taken the internet by storm recently is DALL·E 2, a model created by OpenAI that can create realistic images and art from short text prompts. For example, one might prompt the model with the phrase, “a monkey eating a banana while hanging upside down from a walnut tree floating through the sky,” and receive exactly such an image. I prompted DALL·E 2 with the phrase, “happy employee using their laptop and basking in the glow of AI-powered success while their team cheers them on, impressionist style,” and this is what I got in return.

Then, I gave DALL·E 2 the phrase, “venture capitalist adding value to portfolio company, impressionist style,” and received the following. Setting my pride aside, I could appreciate that it did its honest best with such an inherently difficult task.

What’s Next for Large Language Models
Foundational advancements in machine learning have historically led to new software applications and business opportunities. Take computer vision, as an example. In the 90’s and early 2000’s, computer vision was a well-traveled, but often unfruitful area of research; early algorithms were only capable of detecting edges, corners, and basic shapes.
In 2006, Fei-Fei Li, a computer scientist from the University of Illinois, realized that data was the key ingredient for success with computer vision, and she proposed ImageNet, a public database of annotated images. By 2012, ImageNet contained millions of crowdsourced images, and a model called AlexNet that used it achieved image recognition accuracy that blew away all historical results. In the last decade, the foundation laid by Fei-Fei Li’s data insight and ImageNet have enabled incredible applications of computer vision including self-driving cars, facial recognition, cancer detection, and more.
At BCV, we view large language models as a similar foundation with broad implications, and we’re particularly excited for the implications in B2B software. The dominant form factor of enterprise software today is that of a database with a user interface. Much has changed from the early days of SAP to today’s world of Rippling, Airtable, and Carta. Applications have moved to the browser, interface design is no longer an afterthought, APIs enable connections to other databases, but the database paradigm remains.
LLMs enable applications to hold much more information and history in context and surface relevant pieces in a natural manner. Intelligent applications will require less dragging and dropping, pointing and clicking, hunting and pecking. One might imagine simply ask their HR platform, “how’s morale been amongst my engineers recently?” or their relationship management software, “who should I meet when I visit New York next week?” New, vertical application companies will arise to deliver this intelligent and intuitive paradigm, and we look forward to getting to know them.
I would kindly request you to restart your writing in your newsletter. Really appreciate this content.