
Function as a Service w/ Firecracker

If you enjoy this article or are thinking about similar things, I’d love to discuss with you, so feel free to reach me at scrowder@baincapital.com or on Twitter @samecrowder.
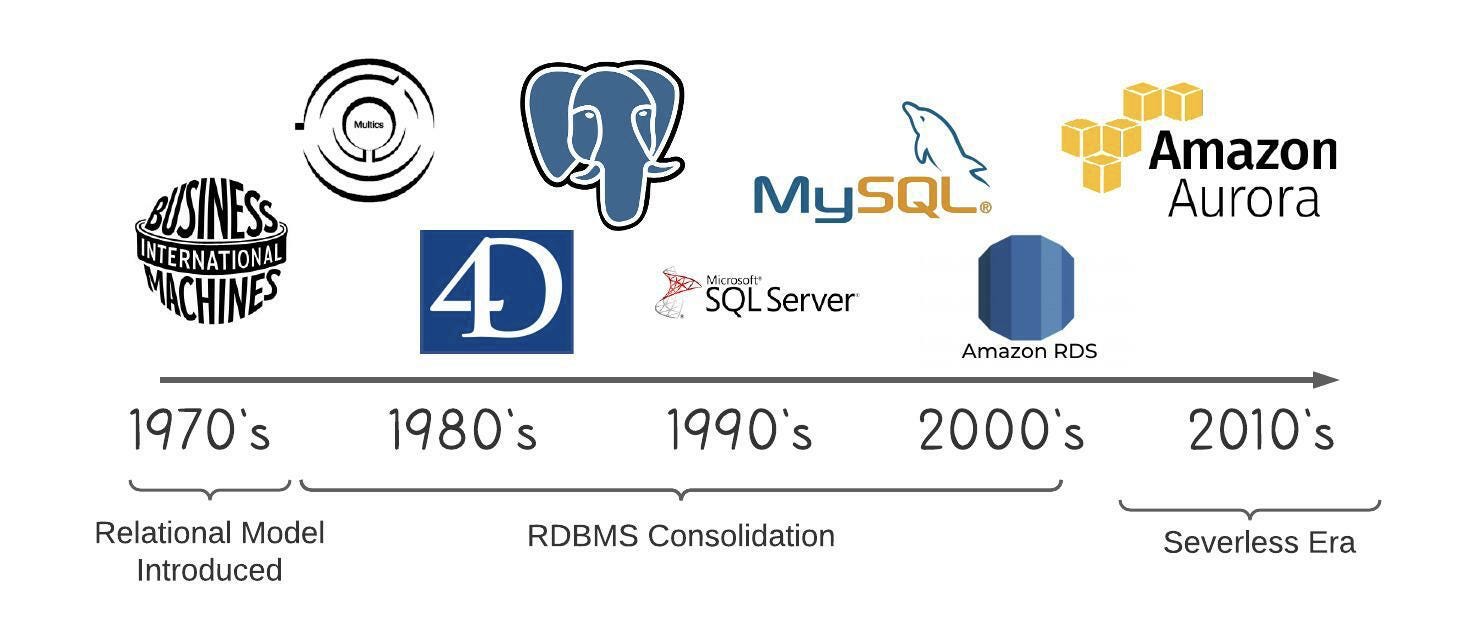
Many subspaces within infrastructure software can effectively be modeled as increasing layers of abstraction built one on top of the other over the course of decades. Take, for example, the history of relational databases. The term was first proposed in 1970 by E.F. Codd at IBM as the idea to present data to end users as relations in a tabular format. A few years later, IBM began its work on System R, a first of its kind relational database. To interact with the system, users were required to make manual modifications to their operating system to create a writable piece of shared virtual memory.
The first commercial RDBMS system was Multics Relational Data Store, which took much of the install burden off of end users, but required a separate set of commands for meta operations like creating and deleting tables. Fast forward to 1984, and Apple released the first relational database for Macintosh computers. 4th Dimension, as it was known, included a fully featured SQL back end, integration of PHP, and even interface plugins for less technical users. Anyone who wanted to use a database no longer had to think in terms of operating system configurations, but now in terms of SQL commands and data visualization.
Skipping ahead many generations, today’s cloud-native developers can go to the AWS console and spin up an [Aurora](https://aws.amazon.com/rds/aurora/serverless/#:~:text=Amazon Aurora Serverless is an,scaling configuration for Amazon Aurora.&text=You pay on a per,the Amazon RDS Management Console.) instance. These developers don’t even need to think in terms of the machine on which the DBMS is running, but only in terms of their application data, a much higher level of abstraction.
A Higher Abstraction of Compute
A similar trend is clear with compute and application logic. One of the recent trends in that domain is Function as a Service. Sentinel One defines Function as a Service (FaaS) the following way:
FaaS simplifies deploying applications to the cloud. With serverless computing, you install a piece of business logic, a “function,” on a cloud platform. The platform executes the function on demand. So you can run backend code without provisioning or maintaining servers.
AWS Lambda (2014) was the first offering of Function as a Service from any of the major cloud providers. It was soon followed by similar offerings from GCP, Azure, IBM OpenWhisk, and Oracle Cloud Fn. Common use cases for function as a service include data processing, IoT, and mobile/web app servers.
One benefit of serverless compute is built-in scalability without any configuration from the developer. Spend less time selecting server options, and more time on your core differentiation. Also, serverless compute has cost advantages with certain workloads because developers don’t pay for hardware costs for the amount of time their application is deployed, but only when the functions are in use.
Of course, the FaaS model can be abused and ultimately lead to more complex app architectures with less visibility if not used with care:
Let’s not despair. Netflix, for example, is an interesting case study in effective serverless app development. Their cloud deployments operate at such scale that in Q3 2019 alone, they delivered 7 billion hours of video to 50 million customers across 60 countries. They used 50,000 instances across 12 availability zones with 50% of those instances turning over every day.
Neil Hunt, Netflix’s Chief Product Officer at the time, described in an AWS Reinvent talk compute’s version of the increasing layers of software abstraction with the following list:
Buildings + power
Processors + wires
Assembly code + protocols
High-level languages
Operating systems (abstract management of hardware)
AWS APIs
AWS Lamba
At the end of the day, anything that gives developers previously unknown superpowers is going to be a useful infrastructure product, and it’s the kind of thing that I love to see as an investor.
AWS Firecracker to the Rescue
With hyperscalers like Netflix running such large serverless deployments, AWS has come to need a low-level mechanism to squeeze every last drop of efficiency out of their hardware. Firecracker, by AWS, was developed in response to such scaling issues. Firecracker is an open-source technology that provides secure and fast microVMs for serverless compute.

MicroVMs are a concept somewhere between full VMs and application containers. They were initially pioneered by Bromium, a company which raised $40M from a16z, Ignition, LSPVP, Intel Capital, and a few others before being acquired by HP in 2019. MicroVMs offer the security and isolation benefits of full VMs (virtual machines), given they each have their own operating system and kernel. The virtualization between resources is maintained at the hardware level, like with VMs.
On the other hand, microVMs have the speed and density properties of containers. When AWS started to build Firecracker, they initially wanted AWS workloads to run in separate VMs for security purposes, but overtime they found they needed a more efficient and lightweight solution. Firecracker has even become so lightweight that it’s about 100x faster than Docker containers on cold start.

Firecracker was designed for serverless workloads, so it doesn’t require numerous features usually included in virtual machines. These include features like USB, displays, speakers, and microphones. At peak performance, Firecracker can instantiate up to 150 microVMs per second per host and run with a memory overhead of less than 5 MiB!
microVM Security Posture
Additionally, the architecture of a microVM adds security benefits above what containers are able to provide. Since microVMs run a guest operating system, they rely on a guest kernel and don’t interact directly with the host kernel. Container engines are able to limit security vulnerabilities by limiting system calls that containers are allowed to make, but this comes with an inherent trade-off in functionality.
Firecracker depends on KVM (Kernel-based Virtual Machine), which ships with standard Linux distributions. KVM turns Linux into a hypervisor which gives you the ability to run the guest operating system that a Firecracker microVM depends on. Under KVM, each virtual machine runs as a standard Linux process with dedicated virtual hardware such as memory, CPU, and disk.

Fun fact: prior to AWS building Firecracker to give Lambda more agility, Lambda gave each customer their own EC2 instance for the sake of isolation. That’s how concerned AWS was about the security implications of untrusted code running directly on the host kernel!
Opportunities in FaaS
Such fundamental components to FaaS development like Firecracker (or like containers, for that matter) remain as difficult to commercialize as they are crucial to the modern dev stack, but a few opportunities stand out to me in this space:
Serverless application monitoring - Datadog offers serverless monitoring solutions for Lambda and other serverless providers, and AWS has their own offering for Lambda. The problem is with the explosion of units of business logic under this new computing paradigm. Kubernetes has its own set of challenges with application monitoring due to broad application distribution, and serverless takes this characteristic to the next level.
Serverless application analysis - More traditional applications utilize a whole host of architectural analyses like static code analysis, cyclomatic complexity, and application cohesion. A new set of tools is likely required for software architected so differently. At the very least, this represents an opportunity for open-source developers, if not also a large commercial opportunity.
Local development enablement — Traditional microservice and serverless architectures are as different as day and night. Serverless enables quicker time to production, but developers struggle with local development as their application stack is even more fragmented than with traditional architectures. Something like Serverless Stack is interesting for this purpose.
MicroVMs like Firecracker have impressive technical properties that enable creativity and flexibility at the application layer, in which case everyone wins. As an open-source geek and an early-stage infrastructure investor, I’m excited to continue following the serverless space!
You are hitting on some real pain points, especially the one about local development being more difficult.