
dbt (data build tool) + dbt Labs

I haven't written in a while, as I've been busier at work, and I've also taken some time to think and figure out what specifically in the world of software I'm most interested in and want to spend my time reading and writing about. After a lot of thought, I've developed a more narrow definition of what I want to accomplish with these articles.
The purpose of the blog is to discuss instances when cloud computing has created a need for new or improved software infrastructure and that need has been met by a new technology built by a startup. First, it's important to give a crystal-clear definition of cloud computing.
Cloud computing is a software model in which applications are run on shared computing resources which are not owned or managed by the party running the application.
In its most simple form, when you go to google.com and run a search query, that query is executed on hardware operated by Google, not by you. That's cloud software. Now, while cloud apps like Google's are cool and merit lots of discussion, I'm most interested in the software infrastructure that gets built because cloud computing continues to fundamentally change the software landscape and what is possible.
The quintessential recent example is Snowflake Inc. which builds data warehousing technology and has grown to $600M+ in revenue just since 2012. Cloud computing made hardware resources elastic and isolated from the perspective of end users (i.e. you can rent X CPUs and Y TBs of storage if that's what your workload requires at the moment; no need to estimate and provision ahead of time). This new elasticity created by the cloud constituted an opportunity for someone to build a cloud-native data warehouse that behaves in this elastic manner and gives users the resources they need when they need them. Snowflake saw this tech trend early and built a product to address it.
That's why I'm calling this blog Cloud Constructed. Cloud computing continues to have a huge effect across the software infrastructure stack on both what's possible to build and what businesses need. Today I'm going to go over DBT Labs and its open-source product, dbt, and how its very existence can be explained only by the rising popularity of the cloud.
Introduction to DBT
dbt stands for data build tool and **is an open-source python project that makes it easy for anyone to transform datasets using SQL. The common usage pattern for dbt is that an enterprise loads massive of amounts of less structured data into a warehouse and then uses dbt to refine and clean that data, generating a resultant data set that's smaller and easier to mine for insight.

Users of dbt transform data by writing sql SELECT queries and running them in sequence on source data using dbt commands. With such a simple interface, anyone who knows sql can play the role of data engineer and manage complex transformations. This is why dbt labs has created the concept of an "analyst engineer", actors with the skillsets of data analysts but now the abilities of engineers.
For a bit more information on dbt and its semantics, see the blog I wrote a few weeks ago on integrating dbt with what we're building at Rockset!
The ETL Process
The story of dbt's rising popularity starts with what's known as ETL, or "extract, transform, and load." ETL has been an industry term and standard since the early days of the enterprise computing revolution in the 1970's. Extract, transform, and load describes the process in which large amounts of data are copied from a source location, transformed to meet a business' needs as best possible, and then loaded into any kind of destination database where it can reside permanently and serve analysts, application developers, and other functions.
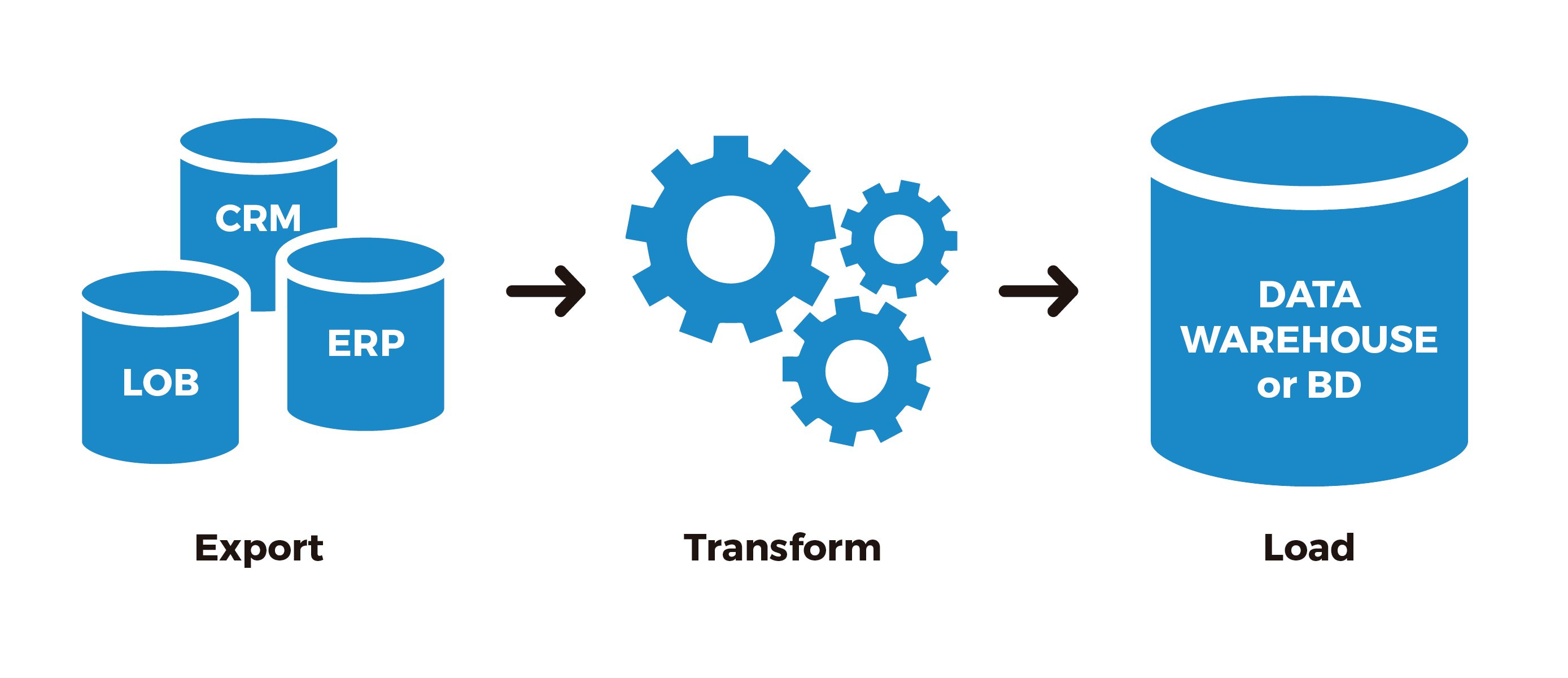
You may notice the difference between how dbt is used and the typical ETL process described here. dbt has played a part in flipping the script on this industry standard of 40 years, as it enables transformation after the data loading step, or *"*ELT" if you will. However, dbt's popularity is more symptom than cause as part of this trend, as the real explanation behind "load" and "transform" switching places is cloud computing, particularly in changing storage economics and providing added schema flexibility.
The Cloud Effect on Storage + Schema
In a cloud computing model, of course hardware is needed to store business data, but the way in which hardware scales operates completely differently. In a self-managed model, as data size grows, hardware needs grow, and thus additional servers must be stood up alongside existing infrastructure with some amount of lead time and an increased need for an in-house team to manage that hardware.
With the cloud, hardware appears to be completely elastic to the end user, and thus scaling it horizontally is much easier. This ease of use has contributed to increased data sizes possible in enterprise warehouses. Also in the cloud, additional disk space can be seamlessly provisioned for temporary periods of time, allowing one to scale up when performing transformations that require ephemeral tables with redundant data copies and scale down when these tables are no longer needed. Dbt-style transformations are made possible with this short-term hardware elasticity.

Another technical advantage of data warehousing in the cloud as opposed to in legacy environments is in schema flexibility. The rise of the enterprise cloud has helped to grow the popularity of object storage systems, in which data is addressed as arbitrary-sized chunks or blobs distributed across numerous servers. The near-instant elasticity in the cloud allows users to store whatever data in whatever format they desire, improving the schema flexibility available to them.
And with this schema flexibility, the appeal of a product like dbt makes a whole lot of sense. If you're no longer constrained to uploading data to a warehouse according to a pre-defined schema, why not upload data in a more raw form to the warehouse and transform it after arrival? The popularity of dbt can be directly explained by the cloud model.
DBT Labs
With these cloud tailwinds, it's no surprise that dbt is one of the fastest growing open-source projects in the infrastructure world, with over 3.2k stars on github. And dbt is more than just a popular open-source repo, but a rapidly growing company as well. Dbt Labs (the makers of dbt) offers a hosted service called dbt Cloud with the kind of features that you might expect from an open-source business model, including monitoring, CI/CD, and a cloud-based IDE. Congrats to dbt Labs on their Series C raise from Sequoia, a16z, and Altimeter announced a few weeks ago!